
Source:https://www.differencebetween.com/difference-between-l1-and-vs-l2-cache/ Difference Between L1 and L2 Cache | Compare the Difference Between Similar Terms L1 vs L2 Cache Cache memory is a special memory used by the CPU (Central Processing Unit) of a computer for the purpose of decreasing the average time requ www.differencebetween.com 캐시 상대적으로 용량이 작고 속도는 빠른 메모리. 메인 메모리에서 자주 쓰이는 데이터를 저장한다...
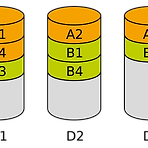 Data Striping
Data Striping
source: https://en.wikipedia.org/wiki/Data_striping Data striping - Wikipedia In computer data storage, data striping is the technique of segmenting logically sequential data, such as a file, so that consecutive segments are stored on different physical storage devices. An example of data striping. Files A and B, of four blocks each en.wikipedia.org 컴퓨터 데이터 저장에서 data striping은 논리적으로 순차적인 데이터를 나누..
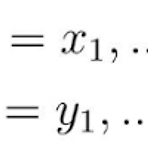 Random Forest
Random Forest
https://en.wikipedia.org/wiki/Random_forest Random forest - Wikipedia From Wikipedia, the free encyclopedia Jump to navigation Jump to search This article is about the machine learning technique. For other kinds of random tree, see Random tree. Binary search tree based ensemble machine learning method Diagram of a random dec en.wikipedia.org Random Forests 혹은 Random Decision Forests는 분류classific..
Source: machinelearningmedium.com/2018/04/08/error-metrics-for-skewed-data-and-large-datasets/ Error Metrics for Skewed Classes and Using Large Datasets The error metrics like mean-squared error do not work for highly imbalanced class. Also, why is it that using larger dataset is always advised? machinelearningmedium.com What are Skewed Classes? Skewed classes basically refer to a dataset, where..
God, grant me the serenity to accept the things I cannot change, courage to change the things I can, and wisdom to know the difference. 신이시여, 제가 바꿀 수 없는 것을 받아들일 수 있는 평온을 주시고, 제가 바꿀 수 있는 것들을 바꿀 용기를 주시고, 이 둘을 분별할 수 있는 지혜를 주소서. 유명한 기도문인데 여러 변형이 있으며 그 중 위의 문장이 널리 알려져 있다. 문장의 아름다움은 시간을 타지 않는 거 같다. 중학생 시절 스쳐지나가듯 어디선가 읽은 글이 눈에 아른거려 원문을 계속 찾아헤맸었다. 첫 눈에 반했었는데, 지금 읽어도 여전히 아름답다. 그냥 오랫만에 이 구절을 읽게 되어서 글을 써 본..
fmincg 라는 함수는 MATLAB과 Octave 에 없는 함수이다. 이 수업을 위해 고안된 helper function이다. fminunc를 모방하여 만들어졌다. function [X, fX, i] = fmincg(f, X, options, P1, P2, P3, P4, P5) Minimize a continuous differentiable multivariate function. 연속적이고 서로 다른 여러 입력을 가지는 함수를 최소화 한다. The starting point is given by "X" (D by 1), and the function named in the string "f", must return a function value and a vector of partial deriva..
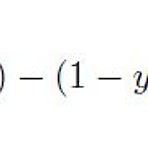 문제를 똑바로 보자
문제를 똑바로 보자
Logistic Regression의 Cost Function에 Regularization을 적용한 식이다. 반복문 없이 행렬로만 계산하는 코드를 작성하였는데 두 가지 실수 때문에 하룻밤을 넘겨서야 해결 할 수 있었다. 1. Regularization은 Theta_0 혹은 제일 첫번째 수식에는 적용하지 않는다. 첫번째 theta는 항상 0이다. 2. log(1-h_theta(x))인데, 1-log(h_theta(x))라고 생각하고 코딩하여 틀렸다. 1번을 깨닫고 난 후에는 모든 게 맞다고 생각했는데, 아무리 돌려도 expected value가 나오지 않아서 정답을 너무나 찾아보고 싶었다. 그래도 꼭 혼자 풀어봐야 할 문제라는 생각이 들어서 몇 시간을 골몰한 끝에서야, 2번을 고치고, 원하는 값을 얻을 수..
출처: www.theatlantic.com/education/archive/2018/10/what-my-harvard-college-reunion-taught-me-about-life/573847/ What I Learned About Life at My 30th College Reunion “Every classmate who became a teacher or doctor seemed happy,” and 29 other lessons from seeing my Harvard class of 1988 all grown up www.theatlantic.com This translation is not written for commercial purposes, definitely. What I Lear..
Batch gradient descent는 전체 example를 한번에 다 통과시킨 후, 그 중에 최적의 값을 찾는다. theta 값이 업데이트 되지 않고 최초의 theta 값으로 전체 example을 계산하고, 그 전체의 평균으로 theta를 업데이트 시킨다. Batch size = Size of Training Set Stochastic gradient descent는 한 번에 하나씩 example을 통과시킨 후, 점진적으로 최적을 교체한다. 그러므로, theta는 example 갯수 만 큼 업데이트 된다. Batch size = 1 따라서, Stocastic gradient descent가 더 정밀하지만, 속도는 Batch gradient descent가 훨씬 더 빠르다. Mini-Batch Gra..
Coursera week1, Gradient Descent For Liner Regression. 아래 내용을 이해할 수 없었음. For the specific choice of cost function used in liner regression, there are no local optima other than the global optima. Note that, while gradient descent can be susceptible to local minima in general, the optimization problem we have posed here for linear regression has only one global, and no other local, optima; thus g..