
티스토리 뷰
source : www.kaggle.com/learn/pandas
Learn Pandas Tutorials
Solve short hands-on challenges to perfect your data manipulation skills.
www.kaggle.com
www.kaggle.com/dansbecker/your-first-machine-learning-model
Your First Machine Learning Model
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
import pandas as pd
file_path = '../inpuit/data-home/example.csv'
my_data = pd.read_csv(file_path)
my_data.describe()
1. Prediction Target
점dot-notation으로 DataFrame의 개별 column에 접근할 수 있다.
Prediction Target은 단어 그대로 분석하고자 하는 대상 column을 의미한다.
예를 들어 LotArea를 Prediction Target으로 삼는다고 한다면, 모델링 이전, 초기 LotArea 값을 y에 저장한다.
y = my_data.LotArea
2. Features
선택되어 모델에 입력 된 column을 Features라고 부른다.
Prediction Target에 영향을 끼칠 것 같은 인자로 다음과 같은 column들을 선택했다고 하자.
lotArea_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']Feature들을 X라는 데이터로 선언한다.
X = my_data[lotArea_features]
X는 다음과 같이 구성되어 있다.
X.describe()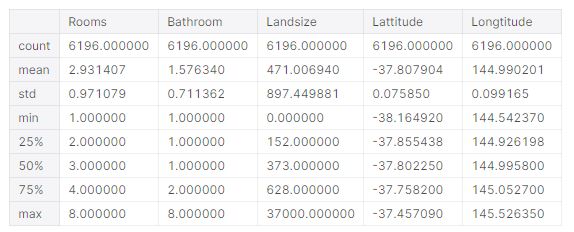
head 함수는 5개 상위 항목만 출력한다.
X.head()
'머신러닝 라이브러리 > pandas' 카테고리의 다른 글
| Pandas 기초 예제 (0) | 2021.01.02 |
|---|